.png?width=180&height=67&name=Crank-AMETEK-HZ-Rev%20(4).png)

Thomas Fletcher, Co-Founder and lead Storyboard product guy, talks UI task prioritization in our Embedded GUI Expert Talks with Crank Software. By watching a replay of Thomas’ live video or by following along the transcript below, understand: how you can take advantage of priority selection and task scheduling for the greatest effect with your embedded user interfaces. You’ll also learn the common priority and scheduling schemes, and how the choices you make in task priority selection can have a significant impact on the quality of your embedded device’s user experience.
Why talk about UI task prioritization for embedded systems?
It’s important to understand that most embedded UI configurations are the operating environments in which they're running. Most embedded UIs are running inside of an operating system or real-time executive and a lot of those configurations are just like their name says, real-time. Real-time means that the configurations are geared around providing a deterministic response. Typically, these configurations are set up so that it's not just a matter of running multiple tasks, but the operating systems and the real-time executives are actually designed to provide you with deterministic, very reliable behavior. If you have timing requirements, then you have certain priorities that need work in order to be complete and that you can ensure are being completed on a regular basis. We can leverage that information and the configuration when we're putting together an embedded UI because now, more and more of these embedded UIs are running on the same systems that are doing the data gathering as well. This means that the same configuration that would apply to your data gathering, in terms of tasks selections and priorities, would also apply to your embedded UI.
Reminder: Real- time executive means real-time that the system configurations are geared around providing a deterministic response.
Let’s start with the basics and built it up
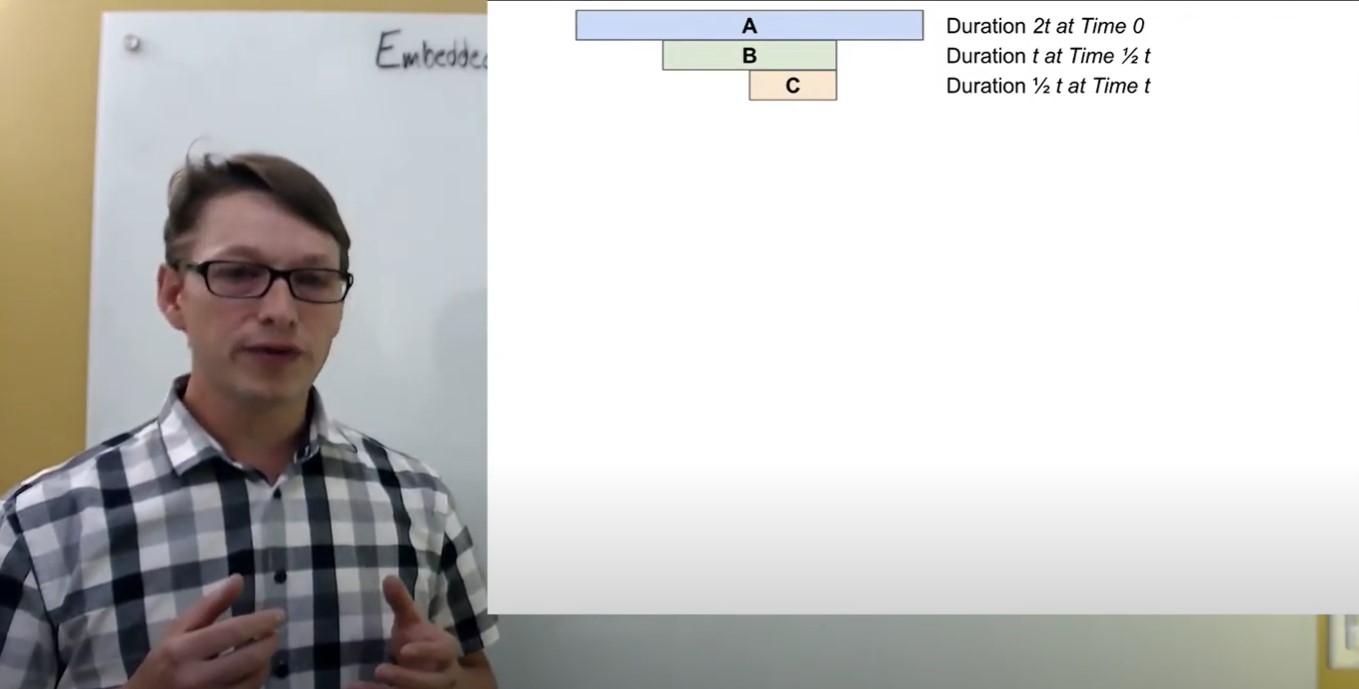
As a little bit of a grounder, I want to give a baseline around scheduling policies and scheduling selection so that it puts our priority conversation into context. I'm going to pull up some slides here, to talk about three tasks: Task A, Task B, and Task C. All three tasks will be executed by the system. This is going to give us a bit of a playground to work with when we talk about why I would make certain task selections.
These are three different tasks and they’re all arriving at different times, a little bit offset from one another. They are all executing with different amounts of CPU resources:
- Task A requires two time slots.
- Task B requires one time slot.
- Task C requires half a time slot.
If we were thinking about how we would execute these tasks in the context of their simple arrival, what we would find is that there would be a configuration that looks like this.
FIFO scheduling or First In, First Out
This is the natural sense of a job. I'm going to execute the job and then look to the next job that's arrived, and then the next job after that, until there's nothing for me to do - and just continue working. This is called FIFO scheduling or first in, first out. The first task to arrive gets serviced all the way to completion, and then the next task is serviced all the way to completion and so on. This is a very simple and straightforward scheduling policy to implement, but it runs a risk of not being very fair - allowing one task to come in and simply dominate the CPU execution. It's not really the sense of what you want in a system, where you’re running multiple activities at the same time.
FIFO, or First In, First Out Scheduling: The first task to arrive gets serviced all the way to completion, and then the next task is serviced all the way to completion (and so on).
Con: A risk of unfair task delegation.
So there's an evolution of this - on top of many different scheduling policies. I'm only touching on a few of them but the most common ones are FIFO and alternatively, a round-robin.
Round-Robin Scheduling
A round-robin scenario addresses the fairness of FIFO's scheduling, a first in, first out scheduling by servicing tasks as they arrive but only servicing them for a certain period of time before pausing and looking to see if there's another task to service or execute on.
In this case, we see our A Task arrive, get serviced but only up to a maximum of T time and then we switch to the next task, which in this case, was B arriving. We then execute that for its determined period of time and then switch to the next task, C, which is only half of the time slice. As soon as we executive for Task C’s allotted time, we are finished for now and pick back up again at A. Again, the idea behind round-robin is that you're introducing fairness and sharing of the processor, and you're doing it in a way that's deterministic in terms knowing that the worst case execution scenario is being delayed by a certain time slice before you get a chance to execute. That could be the number of tasks sharing that priority band and then coming all the way to you. This allows you to calculate what your approximate latency would be on a system.
Round-Robin: Servicing tasks as they arrive but only servicing them for a certain period of time before pausing and looking to see if there's another task to service or execute on.
This is one of the more popular scheduling policies. In fact, the default policy for a lot of embedded UI configurations and even operating systems that are doing fair share, is that they have this sense of a time slice and that you'll either own the CPU for that period of time or you'll execute until you move on.
What does FIFO and round-robin have to do with priority selection?
If we want to start thinking about tasks as certain tasks being more important than others, then when those tasks arrive, we want to execute them right away. This is where we end up with our priority selection. Priority selection is a little bit different comparing operating system to operating system, in terms of the actual nomenclature used in regards to frequently numeric values or priorities. Sometimes zero is a high priority and sometimes zero is a low priority.
An abstract concept: two priority band - high priority, and low priority
In reality, most operating systems such as QNX, FreeRTOS, and MQX, are all going to have multiple configurations anywhere from 12 to 64 to 128 to unlimited priority bands. That gives you a lot more freedom in terms of picking and choosing where tasks execute.
So if we look at our scenario now, what do we see? We decided that in this scenario we wanted B, as an execution task, to be prioritized above the A and C tasks in terms of importance. That means that whenever B arrives, we would like it to preempt and take control of the CPU to performance execution. We can have B scheduled at a high priority. When A arrives, it'll start executing at its lower priority level. This is the same as what we were seeing with round-robin scheduling. Once B arrives, there's an immediate preemption. We switched tasks to B because B is higher priority. We start executing B, we're running all the way to completion because it's the only high priority task that's running. When B finishes, we're going to switch back down and start looking at the lower priority tasks to execute. In this case, because Task A was preempted and still sitting at the front of the round-robin queue, we'll pick Task A up.
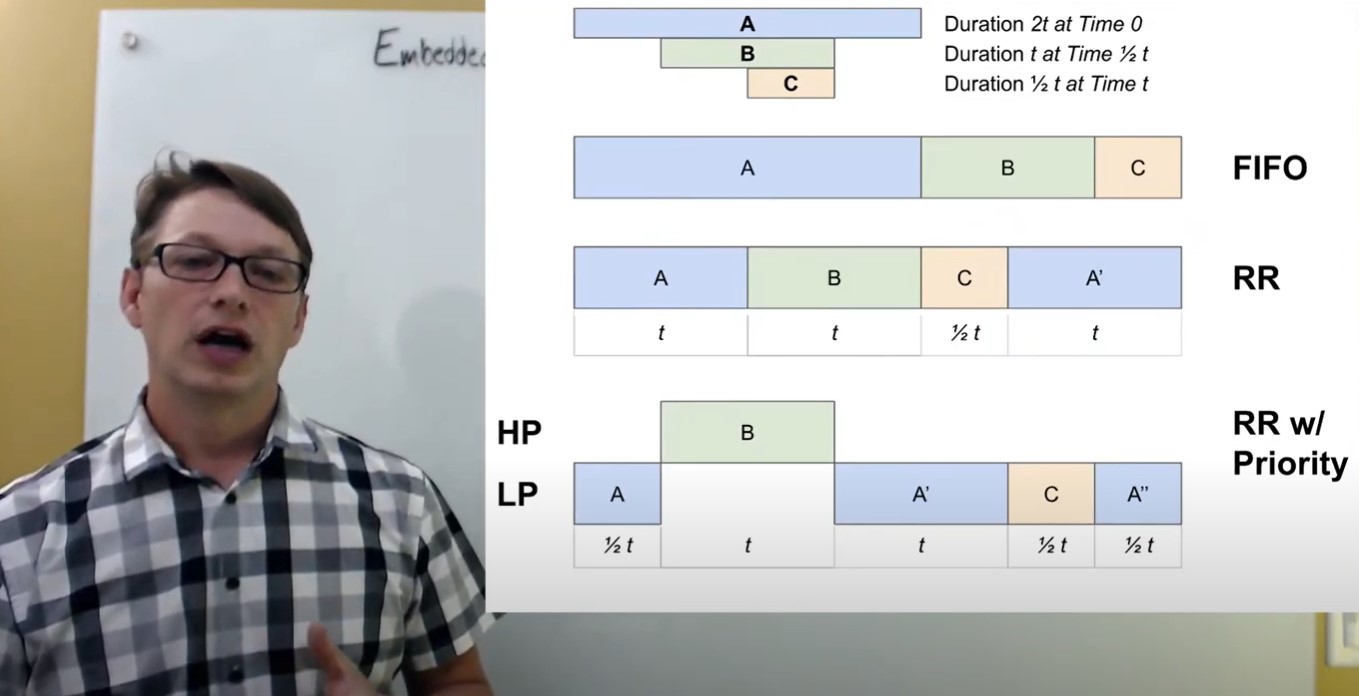
This prioritization could be changed from system to system. Some systems, when they are preempted, will put you to the back of the queue. Some systems will leave you at the front. In our scenario, we decided to leave A at the front. A is going to execute but A is only going to execute for its time slice before it gives control over the CPU to C. From there, C is going to run for its half time slice and then A will pick back up.
This sense of fairness is combined with a sense of importance.
That's really what we're talking about when choosing scheduling policies: round-robin, FIFO (first in, first out), or other scheduling policies that are available. And then scheduling or choosing task priorities in terms of what is the most important thing to run on your system and when you want to have that task executed. That's just a quick overview of task prioritization.
Task prioritization with embedded GUIs
Let's put some numbers in place. When we talk about task priorities and scheduling policies, we're talking about how I configure my system as a whole, all the tasks in the system, what's important to run, what's not important to run, and how long these things need to run for.
When we're talking about embedded UIs or user interfaces, we're talking about wanting to achieve a relatively smooth drawing rate and we've walked through what that means in our past Embedded GUI Talks.
When we talk about smooth animations and movement across the screen, we're talking about 30 to 60 frames per second.
This is a good ballpark to be holding yourself to. You can go a little bit lower in certain scenarios but it really depends on the nature of the embedded user interface. In terms of time, that translates to somewhere between 30 and 15 milliseconds when doing rendering. So this is 30 to 15 milliseconds in between my frames. That's the gap time that I'm allowed to have if I would like to have a smooth visual experience.
These are important numbers because now I can put this in the context of the rest of the system that's being executed, the data collection tasks, and the input task. I can understand if I need this to be the latency on tasks, that ensure that I come back to do my rendering in a timely fashion. This is the number that I'm working with now.
Benchmarking response times for embedded UI tasks
There are some other numbers that are worthwhile to note as well. Because we're talking about user interfaces, a lot of times we're also talking about user input. To follow are the rules of thumb or best practices that are coming out of studies involving analysis of people's interaction with user interfaces.
1. Instantaneous feedback
- 100 milliseconds maximum allowance for instantaneous feedback.
2. Response time
- 250 milliseconds is the average response time.
The average response time for someone seeing something visually change and their ability to react is 250 milliseconds. So when we're thinking about user input, we're thinking about thresholds that sit somewhere between 100 milliseconds and 250 milliseconds in terms of feedback to the user on what's going on. You then want to put that into context of what the feedback is. Is it animated visuals? Then we need to think about the rendering time that those visuals are going to have.
Two considerations: 1) Response time and 2) feedback, and then how long it’s going to take to actually provide rendering.
3. Web interactivity
- One second for web interactivity (for people to stay engaged with your UI)
One second for web interactivity, for people to stay engaged with the webpage, or to stay engaged with a UI. Another rule of thumb is that you don't ever want to be seen as going off the rails or disappearing for no more than one second. This is your feedback loop to make sure that people feel like they're still engaged with your embedded UI.
Input and rendering in your embedded UI environment
I'm going to ignore the system configuration, the data gathering, and all of the other activities that go on in embedded systems because those all have their own time priorities and time restraints that need to be met. I'm going to restrict the conversation here to look at two aspects of the embedded UI environment: input and rendering.
These two elements are fairly important for interactive UIs because we want to make sure that we're putting that feedback and presentation in the context of the rest of the system. You need to be able to gather data in a timely fashion and then once you've done that, feed it back into the system. From there, we can take this conversation and take the input side of it and apply it to the data as well.
An embedded systems example
Let's start out with the configuration where we might say, naturally, as a high priority task and as a low priority task - I want to consider my input and the feedback that I'm getting from the user. This might be on my touchscreen driver, the polling loop, or the interrupt controller. When I get that input, for example a press event, how do I respond and then draw with my embedded UI?
We use the rendering block!
The idea here is that as soon as I get a user input, I want to be able to turn that around. I want to be very quick and responsive. I'm going to put that as a high priority task and feed that data to my UI - which is blocked most of the time. I'm going to put that as a low priority task. It's going to feed that data down.

If I did that, then what I might find is for single press events, I get a nice story. I get a fairly responsive UI because as soon as my input is occurring, it's feeding data into my UI. The input then stops and the UI displays, renders the content, and processes the data.
What happens when you start seeing lots of input events in your embedded system?
Think about what happens when you're interacting with a scrolling list. In this type of scenario, your inputs are going to start bombarding your UI. If you run your input mechanism at a higher priority than your UI, then this will start fragmenting. We talked about this being preempted. My rendering that was occurring here needs to stop. And then maybe I get a little slice of rendering in here. And maybe these were motions. I'll just put a big M here for motion events (see highlighted area below). Eventually what I get is an input event and this is going to be my release.

The problem that is occurring now is that I'm still responding to my first rendering activity while all of these other input events are occurring. Something has to happen with those input events as well. They are being queued and fed into the UI in terms of an input mechanism. That means that because my rendering is occurring after at a lower priority, I'm going to start processing all those motion events afterwards and then releasing events. What happens then is you’ll see a lagging notion as I click on something and drag it around.
To correct lagging with multiple inputs occurring
To fix this, there's compression that happens in here where those motion events will be compressed together. So that instead of here, we have two motion events and then when we release those motion events, they get compressed together into a single motion event. You'll then drop this event. You will only work with the latest one, or maybe drop all of them all the way to the release in which case you're not lagging anymore - but what you're getting is a feeling of jumping right into the scrolling scenario where I'm going to draw, chunk, draw, chunk, draw.
We don't have control over what the user input is going to be doing. This might be serviced by interrupts. We could then put logic in to say you’d like to preempt but don't want to inject events until the rendering is finished. That's a lot of logic for your input to handle. The compression in an embedded UI framework, like Storyboard, is typically handled transparently. With it you can feed as much input in as you want, and Storyboard will compress that input in a smart fashion to give you the best experience - but you're still paying this cost of constant preemption on your rendering path.
Storyboard shows it as an immediate transition but it takes time. It takes time for one task to be torn down, for another task to be started up. So there is in fact, a delta cost here that adds up every time you are doing a task which is preempting. Ultimately, on systems where you may have a low piracy view and every cycle is critical, these deltas can add up rapidly.

That's one configuration where our high priority task is our input task and our lower priority task is the UI and rendering. So let's flip that around. Most UI frameworks, Storyboard included, are going to be event-driven. Embedded UI frameworks are going to sit in a passive state, unless it's more of a movie, HTML, or browsers where something is constantly always going. Our UI, which is now a rendering task, is passively waiting for input. As we receive lower priority input, we can still place these in the system to allow us to have a certain level of responsiveness. When that input occurs, this is our press. We're going to start rendering again and start the data processing or rendering activity. When that occurs, we see the UI has control over the renderings through to completion. This is important because we need to make sure that if we want to have a smooth data flow, that we're sitting between this 30 and 15 millisecond frame timing.
So when I do my rendering here, other input events may be occurring. These may be driven by interrupts. Your hardware may actually drop the events. You may simply see a replacement of the events and that’s natural compression that's happening up here. But when we're finished rendering, we're going to be able to process that again.
Saving time with instantaneous feedback
In order for an instantaneous feedback feel, we want this time here to sit in the 100 millisecond range. In terms of rendering time, we want it to be 30 to 15 milliseconds because the UI being more event-driven is going to be passive until it actually has an activity to perform. If I'm doing an animation, then I can actually interweave these inputs along with the animation processing and to have a smooth rendering experience without segmenting and constantly preempting my rendering, which is actually buying myself bits of time.
Input events and compression with Storyboard
It's a trade off of input and the responsiveness of the input to the scenario of wanting a smooth drawing and feedback. This 100 milliseconds here is all at the control level in terms of your data flow. If I have data flow that's coming in from outside sources, I want to be able to consider the effect on the UI in the same way. I may want to prioritize the acquisition of that data but because of the Storyboard engine, it knows about input events. It's a special class of events that can be compressed. When you're doing your interaction with the embedded UI, in terms of the feedback, you may be looking at introducing compression because you understand the data that's coming in from the outside world and understand can and can’t be compressed. It's a trade off of being able to balance back and forth.
What would happen if we had a round-robin system? If we put this into a round-robin system, my render task is executing. I'm capped here at some kind of timeframe. If I have a time slice that makes sense in the context of how frequently I would like to time slice between my tasks, then I have the possibility that I could end up with, not necessarily an optimal system, but something where I'm getting the best of both worlds and consolidating it all into one process band. Again, there's no concrete answer on these topics in terms of the best thing to do, but what's important to understand is how embedded task priorities and how embedded task scheduling all come together to feed the system and give you a particular experience.
Live Q&A on UI task prioritization in embedded systems
Question: When performing multi-scheduling, is there any potential of each thread accessing memory that belongs to another thread or the RTOS itself?
Answer: Absolutely. That's a consideration we haven’t talked about here. When we talk about these two tasks: our input tasks and our rendering tasks, we're making an assumption that they live in independent worlds. But this communication back and forth has to occur in some sort of shared space. Typically, an operating system will provide a messaging service between tasks that can be synchronized so that you don't end up with any data corruption between the two elements. This is something that usually takes the form of a message queue or event cubes. Inside Storyboard, we have a similar mechanism and protection between tasks that are executing. You do need some synchronization primitives anytime you have shared data. But again, the operating systems will typically provide that for us and when we use Storyboard IO or the Storyboard Event API to inject data, then that's all covered for you. You don't have to worry about that. There's no shared data that goes back and forth between these two that's not protected by synchronization primitive.
Question: What should be the RTOS tick rate on an embedded UI? Any recommendations?
Answer: That's something that we often see as a consideration for performance improvements. A lot of embedded systems that come with real-time executives, FreeRTOS type of configurations will start out with a tick rate of 10 milliseconds. The challenge there is that if you're looking at trying to render every 15 milliseconds but your system is only doing “bookkeeping” every 10 milliseconds, you're pretty far away from being able to accurately drive in on that 15 millisecond inter-event timing.
There's two considerations. One is the granularity of your clock or the granularity of the system tick. And then in the case of round-robin, there's the granularity of what the time slice piece should be. The time slice tends to be highly configurable. You’re going to look at the nature of the tasks that are executing on the system, not just the UI task, but all of your system tasks and decide what's appropriate here. You need to strike a balance between interrupting tasks too frequently and allowing them to have enough time to actually do the work that they need to do because as I mentioned, task interruption and rescheduling accumulates silent time. Time that's not really accounted for in the system.
So normally when we look at embedded systems, we like to have a 1 millisecond tick rate because 1 millisecond gives us 2 milliseconds of granularity in terms of making time assessments. This is your frequency split rate and you can move that up. You could move it to 5 milliseconds if you're finding that's too taxing on your system. At 5 milliseconds, you're looking at a 10 millisecond granularity because you may have come in to make an assessment to one side or the other. At that point, you can only guarantee that you're truly measuring at a 10 millisecond resolution with a 5 millisecond tick rate. This starts to get into measurement theory and some complicated priority and task scheduling conversations.
Question: Are there ways to reduce the deltas that occur during rendering?
Answer: The first way to reduce those deltas is to avoid preemption. As you look at your tasks and your system, you want to see how frequently things are being interrupted. There are great tools for this available with most real-time executive and real-time operating systems. On QNX, for example, you have your system profiler. On Linux, you have tracing tool kits. On FreeRTOS, you have tools, like Percepio, that give you insights into the system to be able to measure how frequently you're interrupted.
So then the first thing to do is reduce the deltas by reducing the interruption. Get rid of the problem altogether by not having the problem. If you want to reduce the costs here, that's an interesting question because a lot of that is buried at the operating system level. And that is really going to be a processor-specific issue and those costs tend to be pretty fixed. It's not a matter of, I have more tasks or less tasks. Those tend to be fixed. But what you can do is look at the cost inside your rendering block and how much work you’re doing inside the UI rendering.
This is where you want to be able to mitigate the amount of data processing, for example, that you're doing. If I'm responding to a press, I'm interacting with my UI and my UI is doing some work to respond to that feedback. It could be doing two parts of work, maybe it's a button and it’s visually changing. That's going to be my redraw activity, but the button may also be performing in action. That action is going to be executed in this context but we want to move that off to some other context or other tasks as quickly as possible. You need to get it out of the UI and out of the rendering path - into a system path. That can be configured in the context of the rest of the system here. Move the data, being generated by the button in terms of some sort of imperative command, and push it down into lower priority tasks.
You want to move all of your data out that way. It’s good practice because it keeps your UI clean instead of the data-processing zapper.
As you can see, scheduling task priorities and real-time operating systems is a passion of mine. I like to talk about it but it's really important because it's not just a cut and dry solution to “make it high and make it low.” You really have to understand what high and low means and then put it into the context of your own embedded system.
For more Embedded GUI Expert Talks like this one, check out our YouTube playlist for on-demand videos and upcoming live dates.