.png?width=180&height=67&name=Crank-AMETEK-HZ-Rev%20(4).png)


Thomas Fletcher, Co-Founder and VP of R&D and lead Storyboard product guy, talks glue logic, and how glue logic is a connective piece that allows product development teams to build better embedded user interfaces, in our Embedded GUI Expert Talks with Crank Software.
By watching a replay of Thomas’ live video or by following along the transcript below, understand: the pros and cons of 3 types of glue logic, how to implement the 3 different approaches, cost comparisons, and how embedded technologies like our embedded GUI development platform Storyboard, can make implementing glue logic easier.
Or, jump straight ahead to the Q & A session of the live video.
What is UI glue logic?
When talking about user interface elements, your UI is disconnected and separated from your system logic. And oftentimes, in the context of a design pattern, you'll hear of the model view controller, model view presenter, model view view model, etc. These are all examples of different paradigms for keeping the system logic and the user interface logic separate from one another. There’s a general communication patter that’s used to move data back and forth between the system model and the UI model. The data from the system model generally should be adapted to be used within the UI presentation and for that we use what is referred to as UI glue logic. UI glue logic is the small transformational logic required to take a system data input (such as a temperature value) and then transform that into something that the UI presentation can use (such as a color, or a text string with units etc).
How do you achieve the separation of the UI and embedded system components?
MVC, MVP, and MVVM are all different ways in which you can achieve the separation between UI and embedded system, but ultimately they're all concerned with keeping the system model intact and allowing the UI to change its presentation and its way of reflecting data values to your system. This is important for embedded systems because you want to keep that separation clear and clean while working in already constrained environments. We want to have the freedom to optimize individual areas as we see fit, whenever we want to.
Let's imagine we're talking about a thermostat.
If I have a system model, I might have temperature as part of the data that I'm storing in my model. The data could be the current temperature, it could be the set point temperature - but this is a data value and not represented in a particular fashion. It may have an associated set of units with it. So in our case, the units may be degrees Celsius, but we aren’t looking at the data in terms of how it's visually presented - we're just hanging onto the data itself. As we communicate from the model to the embedded user interface, we're going to start interpreting that into the UI.

I'd like to show a value, for example, putting the actual temperature as a label in my user interface. I'll show the value in degrees Celsius, but based on user preferences or formatting, it could also be shown as degrees Fahrenheit. Because of these options, I’ll need to have some sort of conversion logic, or we can take a more visual approach.
Adding visual graphics to represent data values
One of our decisions could be for the temperature to be shown in a bar visual element with an indicator. We can add various coloring to show the differences between cold and hot zones in a visual manner. We can even color this bar element as we're moving it around. There's lots of different ways to represent this. We could even use a gauge element to show the hot and cold changes, with arrow indicators and colour gradients.
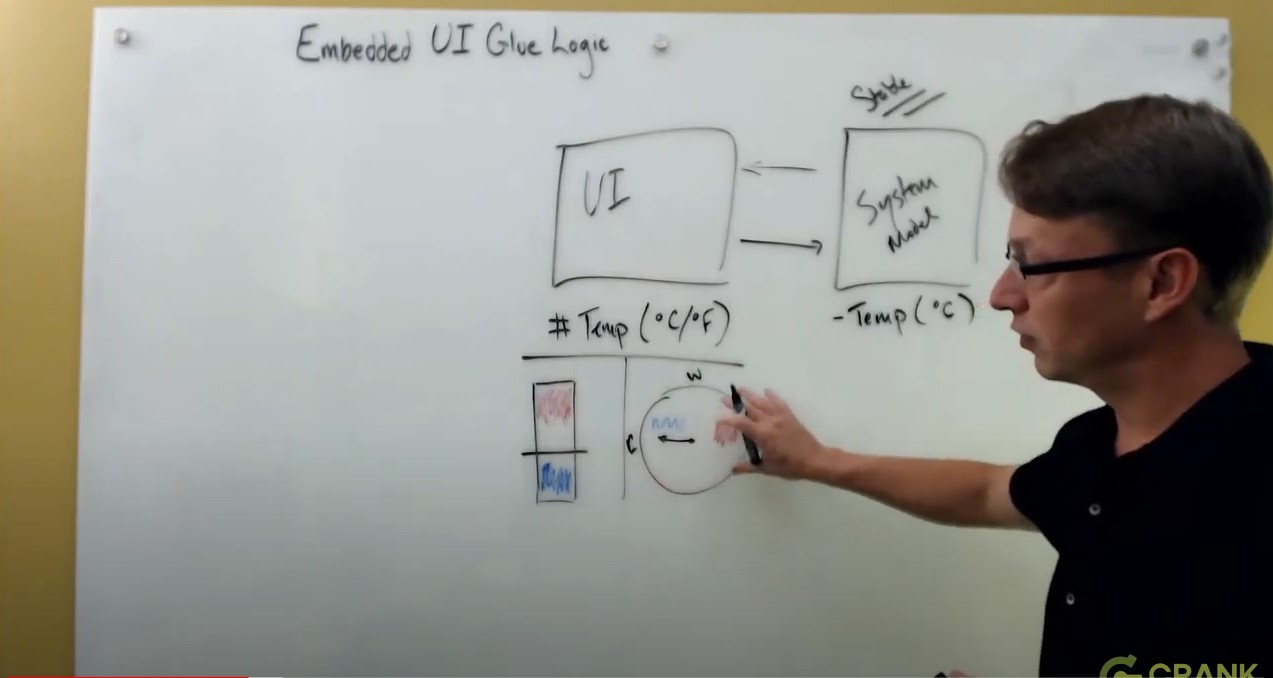
FIGURE 1: the various ways to represent temperature data values
The temperature isn’t changing
What's important to note here is that the temperature is not changing. The value of the model data itself is not changing. The stable data tends to be in the model and doesn’t change very often. This is crucial because when we're talking about what it takes to actually show these various visual representations, we're talking about transforming the stable value into something that could be changing relatively quickly in terms of opinion. Someone working on the product development team could look at the embedded UI and say, "No, I think we may need to make an adjustment. We need to make some changes." These new opinions can sometimes come forward in a short period of time and we want to be able to move quickly through the different UI presentations, different UI formulations, representations - and we're not changing the model data.
Using glue logic to separate data and UI elements from the embedded GUI
The glue logic is what's really required in the separation. The glue logic tends to live on the UI side of an embedded system. And if you're thinking about the MVVM glue logic, or the model view view model design paradigm, would be considered the view model. What's happening in the glue logic here is we're taking the stable system model data and transforming it into whatever it is that the UI needs. If it's formatting a label, if it's changing the units, if it's creating a gradient of color to represent the value, or perhaps we're managing the angular rotation here, there are tons of different ways to represent that data.
In using glue logic, you want to have lots of freedom and be able to move quickly. The importance of what you choose in terms of the type of technology you use for glue logic within your embedded system, will dramatically affect your ability to be agile, to be responsive, and to change to alternative presentations of incorporating the data from a stable system model.
The different glue logic approaches
There's no real fixed story around what the glue logic needs to look like in your embedded system. Typically, it's transforming data from one representation to another, and we're not talking today about the transport of how I move data back and forth between the system model and the user interface. That's a whole other topic. Instead, we're going to use the generic terms of events and data payloads, assuming that there's a decoupled relationship between the system model and the embedded UI.
Using compiled languages for glue logic
One of the first ways that we get into glue logic is compiled glue logic. Compiled glue logic typically means using a compiled language like C or C++ to implement callbacks or data transforms, to modify the data that would come from the system model and apply it into the user interface.

FIGURE 2: COMPILED GLUE LOGIC
This works nicely from an efficiency point of view. Typically your language of implementation when you're talking about compiled glue logic is aligned with the implementation for your system logic, and also perhaps your implementation for your UI. If your embedded UI is using a compiled library of functionality, then this could be a great fit. There are some challenges, though. If we think about the pros and cons, one pro is that you get native execution speed. It could be very fast, making it great for your system overall. One of the cons, however, is that the type of people that you need to implement this glue logic are going to be programmers. You're going to need to have programming expertise, familiarity with a tool set, tool chain compilers, potentially deployment concerns to be able to implement this and that's a challenge because we want this UI to be agile and responsive. We want it to be fast moving.
Pro: Native execution speed; very fast.
Con: Need programmers to implement and deploy tool set with expertise
In giving the thermostat to potential users, it should be able to respond to design changes, and implement them quickly. That can be a bit of a problem because we can't iterate those changes too quickly when we talk about compiled glue logic. This is a generalization, but part of the reason we can't iterate very quickly is because we could be in a different domain. We may be working in a desktop environment for prototyping, for user evaluation, where we need to be able to spin changes around very quickly. And when I have a compiled language in the desktop environment, that means that I need to have my desktop compilers, but if I'm deploying to an embedded target, that means I also have a separate compiler and tool chain for that glue logic down for those platforms. This ends up being a build and maintenance effort that now has to be incorporated into the embedded project timeline.
But compiled glue logic can actually slow down the embedded project
Overall, the compiled glue logic, while it does offer certain performance efficiencies, can slow the project down just because of the nature of what you're working with and who's going to be doing that work. That takes me into this second area. What’s the alternative?
If I don't have compiled glue logic or not using a compiled language to do this, what can I use? Well, I could use a similar situation or a similar technology that eases those portability and cost concerns in terms of how much effort is required to maintain glue logic across a variety of environments. For this, I could use a scripting solution. Something like Lua (which is what Crank Storyboard uses), JavaScript, or Python - a scripted solution that is higher level compared to your compiled language.
Using Lua, Javascript, Python and other scripted solutions for glue logic
You’re still going to need a little bit of programming expertise to use Lua, Python, Javascript and other scripting solutions for your glue logic, but these languages are typically designed to have a lower barrier of entry. They're more flexible and easier to work with. It's still a programming effort but more thinking of the logic rather than thinking about the language and programming techniques. What's nice about using these scripting options is that a lot of these languages will have an efficient execution. They will offer comparable execution times for the scope of work that we're talking about.

FIGURE 3: SCRIPTED GLUE LOGIC
With glue logic, we're only working with small amounts of code. This is the connective work. As data comes in, it needs to be transformed. For example, if I want to change a temperature value into a rotational angle, then that's only a small amount of work - I don't need long run efficiency that the compiled code would give me.
Pro: Morphable, easier to work with, no long run efficiency
Con: Additional overhead costs to implement scripting engines
A lot of what I get using a language interpreter is going to be enough - it’s fast and gives me cross-platform capability. At this point, I can do work on a desktop, on my embedded target, and I can work quickly to move changes around because I don't have to go through a long compile cycle and process. This allows me to be responsive to users. So again, why are we talking about glue logic? Because it's a connective piece that allows product development teams to build better embedded user interfaces. There are some challenges, however, depending on your situation. For example, you may be in an environment where the overhead of implementing the scripting logic is too high, as these scripting engines do typically require some sort of additional overhead.
Supporting Lua with embedded UI technology, like Storyboard
In the case of Lua scripting, we can have 80KB to 100KB of storage of just the Lua language interpreter that's required for us to be able to support the language. That could be over the resource capacity of your embedded target, a potential drawback. If I look at the third scenario for implementing the glue logic, it's what I'll call the high level glue logic.

FIGURE 4: HIGH-LEVEL GLUE LOGIC
This is something that is a technology or domain-specific solution. It tends to be associated with a particular technology and works hand-in-hand with that particular technology to lift up the glue logic concept and move it from being a particular programming language or implementation to being a more abstract data concept. If we think about what happens with our thermostat as temperature values change and we want to flow them in, we want to be able to process that data almost as a stream.
Associating a data value with a UI output
We like to associate this temperature value with a UI output and form that association. Some embedded technologies or tools allow us to do those direct data mappings and bindings so that you and your teammates aren’t really programming. There's certainly some programming going on behind the scenes, but that you're working at a much higher level - more data oriented and contextual to the problem that you're solving.
There’s two different approaches here: data bindings and mappings, or flow-based programming:
Data bindings and mappings: Where you have a set of transforms that make an association between when this value is received. i.e. I'd like to process it in this way and I'd like to make an assignment to this output value in terms of the UI.
Flow-based programming: Where you process data as a stream. i.e. You're running it through a series of filters, transforms, conditions and branches, and then pumping that into an output.
Now, if we consider this in the context of scripted and compiled languages, these are techniques that “sit on top” of those two other approaches in terms of how they can be implemented. They are very technology-specific. This means that while you may not need programmers any longer to implement your glue logic, you’re going to need developers who are versed in these specific technologies. That could be part of building up the expertise with a particular technology. This is both a pro and a con. You can become powerful with these domain-specific languages and make a significant investment if that's part of your long term story. The other area is that a lot of these domain-specific languages and techniques are designed to allow you to iterate and move rapidly.
Pro: Iterate and move rapidly
Pro & Con: Build up expertise with technology, significant investment but powerful
Comparing embedded technologies and programming costs
Once you've gone through the language curve or technology curve of learning, you're able to quickly assemble solutions and iterate content for your users. Different technologies have different costs, so it's hard to say across the board whether or not it's going to be a low or a high platform maintenance cost.
Generally, these are technologies that are bound in with specific solutions. This means you can look at your UI technology vendor to assist you with some of the maintenance and importing costs.
Just to give you an idea of what something like that might look like, I have a design sample here within Storyboard. It's an example of what a flow-based programming approach might look like for how you do the data processing. Here (in the live video), you can see that it's very different than going in and doing the programming language yourself.
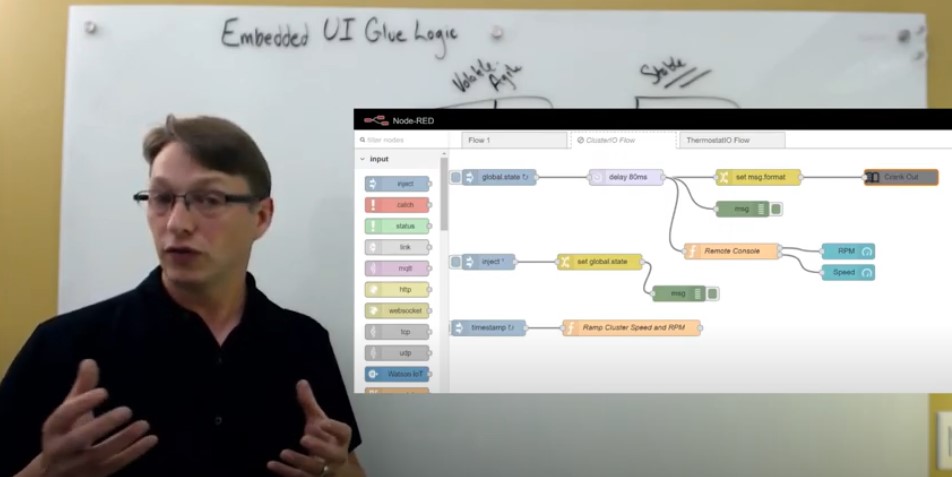
FIGURE 5: using a flow-based programming approach for the data processing
This is mapping out the relationship of incoming data to outputs that can be used for UI presentation and in this case, we're using Node-RED as an interpreter system and then flowing events into the system using our Storyboard IO. This was a sample that we worked on for one of our customers as a prototype. Interesting to look at and an interesting approach overall.
Wrap up: Choosing a compiled or scripted solution for glue logic
I just wanted to highlight where we are with this type of technique. We're looking at transforming data from your model into your embedded UI with glue logic. There's lots of different approaches that you can take to accomplish that. Which one you ended up choosing will really depend on the environment that you're operating in.
If you use a compiled solution, you’re typically going to require a bit more overhead and maintenance from your infrastructure in terms of your embedded UI product being built. That means you’re also going to require a longer cycle for your team to implement change inside of the UI. Programmers will be deeply integrated so they can continue to be responsive.
Using glue logic that involves a scripting language like Lua, JavaScript, or Python will allow you to iterate those changes much faster. These scripting languages will also lower your maintenance and overhead costs in terms of how much cross-platform work you have to do within your builds or product infrastructure.
On the other hand, you're going to require more resource capacity on your selected target - but the flexibility the languages bring in terms of your ability to change the UI and react to users’ iterations, is going to be high. Everybody knows that responsive product teams really win the hearts of users.
Responsive product teams win the hearts of their users
You can use both of these approaches as underpinnings for something that is more domain-specific, a data-binding framework that allows you to talk in the language of your product. In this case, being able to take a temperature value and apply it to color gradient or color mapping without necessarily any intermediate programming, because the domain-specific language is lifting me out of that and giving the problem in the context of the product that I'm working with.
Three different approaches, three different solutions, all equally valid. All of the glue logic approaches will get you to the end result, but with their own pros and cons. Stay tuned for a more detailed live session on that topic!
Live Q&A on using glue logic in your embedded GUI
Is one type of glue logic better than another? Is one stronger at keeping the UI and the data model cleanly separated?
Answer: We haven't talked about implementation of what keeps the model and the UI data separated. This separation doesn't really have as much to do with the glue logic as it has to do with your overall product design, the environment, and the ecosystem that you're sitting inside of. That's why I said we're talking about events and data being transformed. The glue logic itself doesn't have to necessarily play a role. Different languages and techniques can give you various types of sharing, both tightly coupled but still providing you with an API abstraction to give you a clean separation. And because of the different types of environments that you can run in (process-based, task-based), you're always going to have a question of “what does that separation physically look like?” “Is my UI on top of my model, all running inside of one process?” It's not really desirable, but you can certainly keep it clean. If your UI is a separate execution process from your system model, you’ll have a desirable approach to really keep them at arm's length.
You can do this with C or scripting, or any of the other approaches we've talked about in terms of keeping them separate or keeping them together. You just want to make sure that you're not moving the glue logic from the UI box here over into the system model box. You want to make sure that those two do remain separated, because again, this is relatively stable. Your data model for your system doesn't change. If I'm a thermostat, I have set points. I have temperatures. I have different IO capacities. The data is really fixed. The embedded UI is what changes and what varies a lot, so you want to keep this component all together. You don't want to have to rebuild your system model every time you change your glue logic.
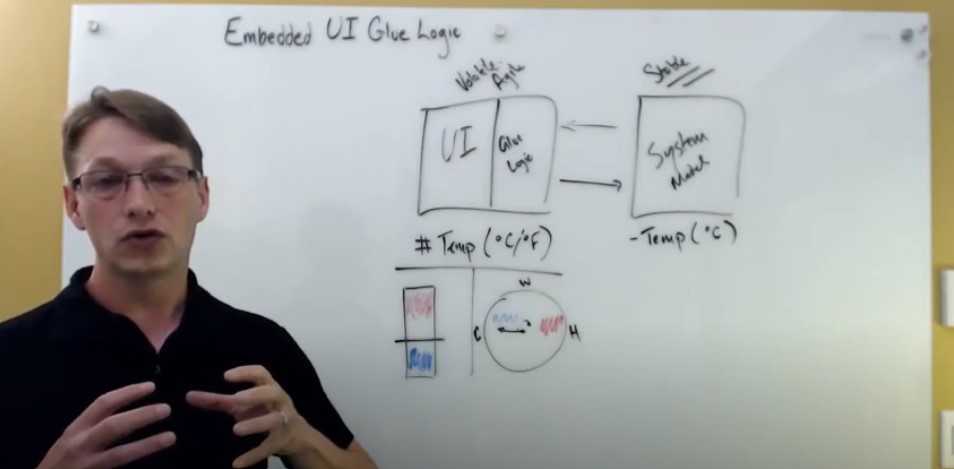
FIGURE 6: MAKE SURE YOU KEEP YOUR GLUE LOGIC SEPARATED FROM YOUR UI ELEMENTS IN THIS THERMOSTAT EXAMPLE
Are there other side benefits for keeping the UI and system data separate from each other in embedded UI development?
Answer: We touched a bit on this, but definitely. Definitely when we keep them separated, you have the opportunity to do things like a hot restart where I may want to do an update to my UI. Again, the data here is all sitting in my system model, executing, continuing to gather data and running on the system. I don't need to power the system down. I can do a soft restart of just the UI component itself.
Now, of course your architecture has to support that. And certainly with Storyboard, our UI design and development software, makes that easy because it has an event-based approach where you could re-initialize and design in an event update that will populate your UI. If this was all combined together into one module, then you really would be forced to do a full system shutdown or restart, which is a lot more interruption for your end user. Software restarts can be measured in fractions of seconds where your power cycling down and up is always going to be longer.
Is there ever a case where using multiple glue logic types would be beneficial?
Answer: That is certainly something that we see. The intent of glue logic is always to be as small and as light as possible. You’re not trying to do heavy computation in your glue logic. Your glue logic is to facilitate the transfer of data from the system model into the presentation, and then from the presentation (usually because you're interacting with the user), back down to the system model. This is really a domain switch. I'm moving from one domain to another.
If you had heavy computation, then you may want to have a C callback approach because you'd like to get that compiled optimization. If you are looking for a lot of flexibility, you can mix and match between the high level abstract glue logic sitting on top of the compiled or the scripted glue logic. And in fact, that happens quite often. Node-RED is a JavaScript framework so it's sitting on top of a JavaScript base. If you needed to drop down into that, you could. In our Storyboard case, we have Lua and it's straightforward to build something on top of the Lua API. We provide the Lua API for communication into the UI that does data binding based on events received or it works with our DOM module, and that provides additional functionality on top of our DOM, representing the UI. This provides the transparent type of behavior of setting a value so that the DOM element knows that if I'm setting a temperature value, I need to format it through a string. I need to convert it to the current setting and units, and that can all be managed transparently.
So yes, absolutely mixing and matching is something that can be done. You probably don't want to go overboard and mix and match everything in all cases, because then you're going to end up pulling out the benefits from all three, but you're also going to pull the detractors out from all three. For example, if I have to have compiled code, that's going to slow me down, even though the majority of my callbacks, the majority of my glue logic here is maybe implemented in scripting logic. You want to be very judicious when you're thinking about mixing and matching, however, certainly going from scripting to the abstract language is something that happens on a regular basis.
For more Embedded GUI Expert Talks like this one, check out our YouTube playlist for on-demand videos and upcoming live dates.