.png?width=180&height=67&name=Crank-AMETEK-HZ-Rev%20(4).png)

Understanding and accounting for the different memory requirements of your embedded graphics application is critical. Your choice of system-level memory (heap, stack, static code), and hardware level can not only impact graphics performance, but also compromise the user experience, and thus market success of your embedded UI.
In this first of two videos on embedded graphics memory optimization, Thomas Fletcher, Crank Software's Co-Founder and VP R&D, talked about the different memory optimization options available for those building on MCUs and MPUs, and how to organize memory use for highest performance. You can watch the replay by clicking the video, or read the transcript pasted below.
To catch part 2 of this series of memory optimization considerations for embedded graphics, jump ahead here.
What memory configuration means for embedded UI development, and the implications of your decisions
There are two broad classifications of memory for embedded systems: embedded flash and embedded RAM. They play different roles in the configuration of your system and they typically your present in some capacity, with different volumes for both.
The nature of flash and RAM memory
The important thing to start off thinking about is - what is the nature of flash and RAM? When we talk about flash memory, we're really talking about persistence. I've got something that doesn't necessarily need to be programmed, doesn't necessarily to be refreshed, while RAM is much more dynamic. With flash being a little bit more persistent, it's typically where you want to put your data, put your code. And RAM being a little bit more dynamic tends to be a little bit more expensive. It requires sort of an ongoing sort of voltage and power to maintain its contents.
The bottom line is, when thinking about performance, you want to think about access speed. How fast can I get data into and out of these types of memory configurations.
Memory for READ
Flash is fast. Generally, when we talk about flash, we're talking about fairly fast access speeds. We're not talking in the context of the UI in terms of what we need to access for visual performance, i.e. in milliseconds? If I'm showing something at 30 or 60 frames a second, I'm talking about 15 millisecond refresh rates that I need to be able to access content, compose it, put it out up to the display.
RAM is very fast . And on the whole, generally we're looking at sort of orders of magnitude in terms of access speed between these two different types of memory configurations.
Memory for WRITE
Flash is slow. Writing is a whole different ballgame because flash is persistent. The writing process here tends to be very, very slow. We're not talking about using this as a dynamic store where I'm actively reading and writing content back and forth. For example, we would not put our frame buffers in the flash.
RAM is very fast. We're very interested in putting that content into RAM because it's very fast.
Typical use cases of Flash and RAM Memory
Given that flash is persistent but it's a little bit slower, certainly slower for writing, and reasonable for accessing the reading content, what do we typically use these two different types of memory configurations for?
Flash is where you put your code. This is where you're going to put your code an data configuration. Anything that requires long term storage.
Put all the variables in RAM. RAM on the other hand, because it's dynamic and fast,is where you want to put all the variables you're going to engage with. All of your Read-Write content and variables.
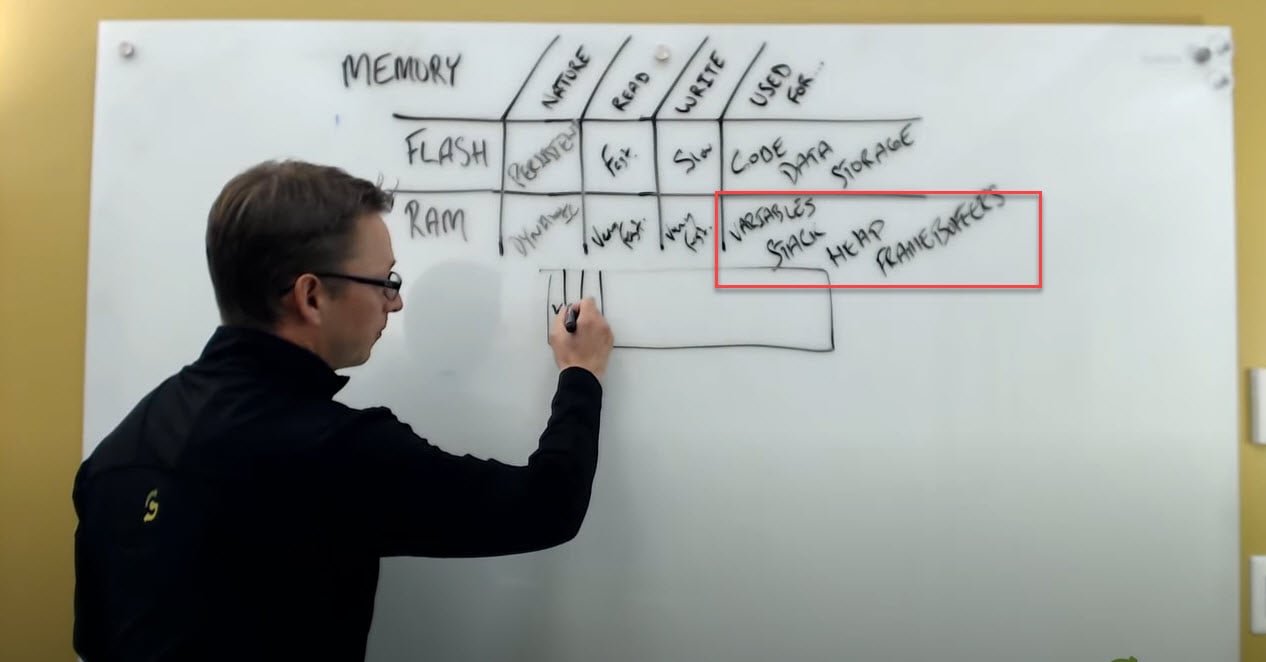
Types of variables for RAM memory
There's all sorts of different types of variables that you're using in that configuration. If thinking about program stack and the execution, some storage space for local variables is required for these. The heap memory is also a type of dynamic memory that we can use. These are all stored in RAM. And, if I bring it back to the notion of embedded graphics, and what may be occupying memory, we also need to consider it being used for frame buffers.
So we’re got the frame buffers, the stack, the heap, the variables. Big topic, we're not going to really explore flash too much today. We're going to leave flash as a place for code data and storage of assets as conversation for our next session.
Now let's look at the RAM flow, and what you could do about optimizing it.
Optimizing RAM flow
If I think about MCU versus MPU configurations, a lot of what you're going to do in terms of memory access is going to be hidden behind the operating system: the Linux, QNX , and Windows system. These are all going to sort of mask your access into RAM. They're going to localize your memory into a process phase where you’re going to virtualize it. Really, when I talk about the configurations today in terms of optimization, a lot of this is really MCU-centric, where you're really building and tightly controlling how your memory is being accessed.
Consider that these are my block of heap (see image below). What we're going to find is that our heap is typically carved up right in to blocks for variables. We're allocating blocks in our heap for our variables, and then what we're doing is the linker is going to also allocate larger blocks here for your stack.
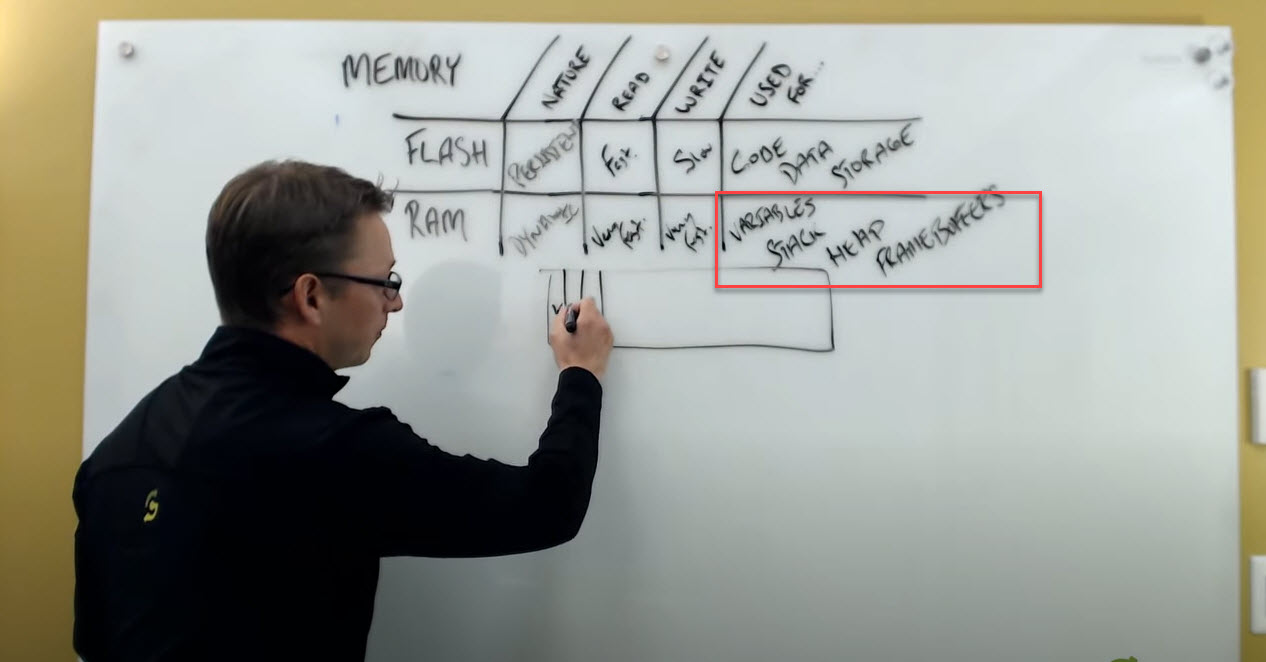
What's the role of the stack and the heap memory?
The stack is where you're putting all of your local variables. This is where when your program is executing and you're going into functions, you need somewhere to store those variables. We're going to have a larger chunk left over, and we're going to allocate that for the heap.
Now, this is an MCU type configuration where everything is tightly packed together. What's really great is that the linker is doing this type packing for you. One of the challenges working with embedded systems is you want to be able to maximize the value of the resources that you have.
Tip #1: If you know in advance how much space your variables and your stack are going to require, all those things can be pre-allocated in advance, typed and packed together into what is really is your block of RAM.
What it looks like in code
If I look at what our code (see image below) is going to look like in terms of the system configuration, what I see is that these stack blocks are going to get used in a very efficient manner. They are also much larger. These variables might be an energy here, or an energy value there. These stack areas tend to be larger blocks of memory. And so, in our stack configuration, what we can do is we can actually look at how that execution runs.
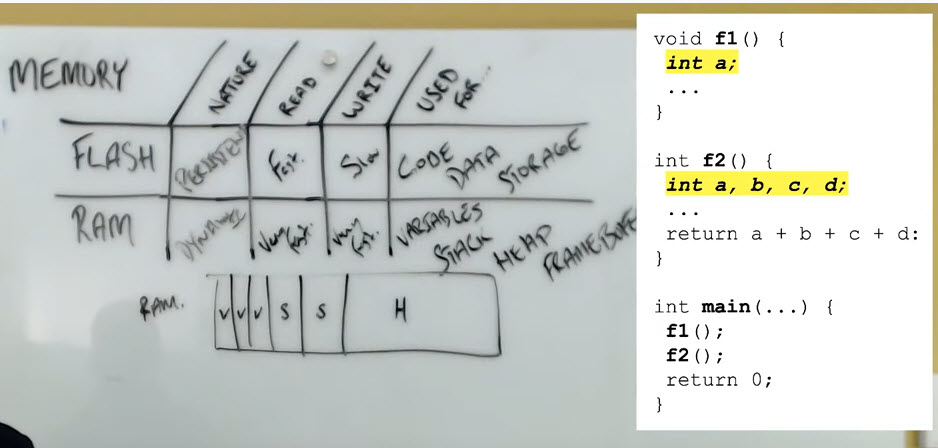
Our stack is a block of memory that kind of accordions up and down. So initially, when you call your program, there's going to be a certain amount of memory allocated for the local variables inside main.
As you call out into new functions,we need to allocate space for that function for those local variables somewhere, where is that int a; being defined. So now what we can do is we can put that memory temporarily on a stack, allocate it, grow the stack up for the duration of that function call, and then when we return, the stack memory usage is going to drop down again.
When we call the next function, in our case the f2 function, what we'll see here is we're going to go and reuse that space for the new variables.
And so there's an overlap. And that's why one of the challenges we have working with embedded systems. We're always looking at static analysis, and provability, but what happens when the C developer returns the address of a variable in the stack?
They're pointing at this memory, and this memory is going to be rapidly reused. You have to be aware of certain variables that you're using, and the addresses that they're coming and how it's being propagated. For example:
- It's OK to use this address going up the stack for the function calls, but
- Not OK to use it going down the stack as you kind of call back out of those functions.
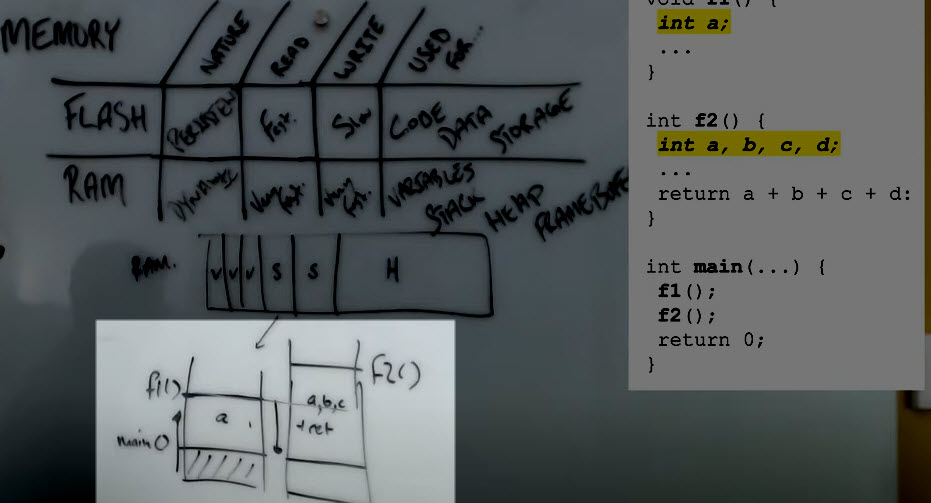
In the above example, you can see F1 and F2 are sharing the stack, but very efficiently. Again, this memory is going to collapse back down to just the main as you accordion it in and out, as you recourse in and out of your call tree.
Stacks are very effective for general management of memory
Stacks really don't offer much of a concern in terms of in our pre-allocated amount of memory, and you always have to consider what’s your maximum usage is going to be. However, they are very effective in terms of sort of general management of memory. Not a lot of concern there about long tier of fragmentation.
Heap usage
Heap memory is what is underlying your mal calls, free calls, your cal calls, your dynamic memory allocations, etc. These all commonly take place out of the heap. There's lots of different policies and ways in which the heap could be managed, but today I'm just going to talk at a high level.
Consider heaps as a kind of continuous block of memory, that gets broken down and subdivided into two main types of uses.
(1) A "small block allocator" where you'd want all the efficiency within your stack. Theses blocks end up being, a sort of 'power of two' subdivision of blocks of memory. So what we might have is, for example, a whole set of memory carved into bins of 8 bytes each, a set of bins at 16 bytes, and then a set of bins at 32 bytes.
This way, when I make an allocation, if I'm looking for 5 or 6 bytes, I'm going to allocate out of this bin block of 8. There is a little bit of wastage and overhead, but the benefit is that I’m very deterministic in terms of my access time. I’m very rapid. I can get into it very fast, and don’t have to do a lot of look up and calculation. I can jump to the right bin size based on the allocation request.
There is going to be a little bit of wastage if you're not hitting the bin size directly. But frequently these could be tuned for your application, right, these allocators. Similarly, you don't end up with any sort of fragmentation because all the bins are the same size. That extra little bit of overhead is a trade-off against not ever sort of losing access to blocks of memory.
(2) A "big block allocator" - For example. Imagine we have a 200K block of memory. I could take 8K and put it in a small block allocator and then divide it up. I might want to leave the other 192K over here, and use those for arbitrarily large allocations (see image below). Under 192K are pretty reasonable - I can put some frame buffers in that space.
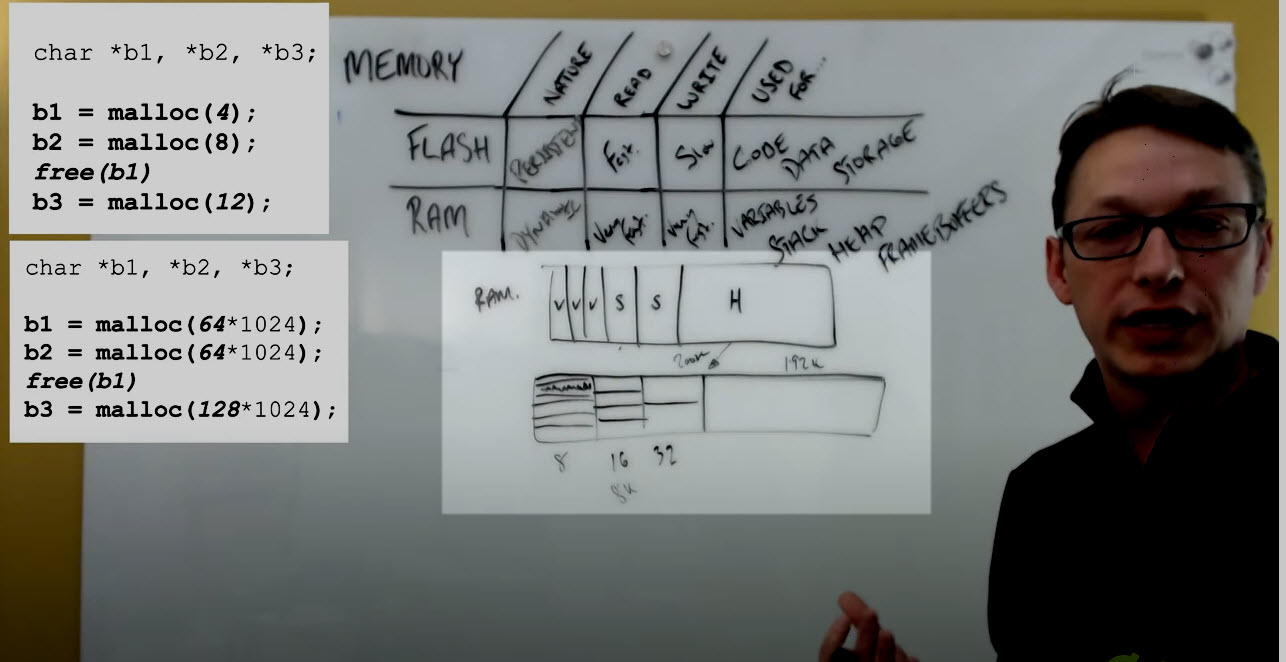
I might see that allocation that comes out of this as 64K, and an allocation of 64K. You can see these sort of coming out in our little diagram above.
Concerns of memory fragmentation
But what happens with this memory when I start freeing blocks? If I allocated first and then second, and then I de-allocated the first block I got this 64K and the 64K block sitting here on the side but now I want to make an allocation for 128K.
I'm stuck. I have it available, but I can't access it because I’ve got this block and need to be cautious of memory fragmentation. This is the downside of working with dynamic memories.
If you make repeated allocations and de-allocations, you run the risk of fragmenting your memory, breaking it up into unusable chunks - especially when we're talking about large allocations.
Tip #2: Pre-allocate your memory as much as possible and put that allocation upfront so as to avoid memory fragmentation.
If you know the allocation patterns of your system, you could further subdivide these and put them into your own custom block allocator. Maybe your small block allocator can't fit, but could be designed for your own particular embedded system, frequently a technique that's used.
Embedded systems don't just work with one block of RAM
Most embedded systems are not working with just one contiguous block of RAM. With MCUs, we generally have several different types of blocks of memory. A sample configuration could be:
- One block of memory here, maybe it's 128K and 'fast'.
- A second block of RAM of 256k that's available but maybe more luminous, and a little bit 'slower'.
How do we want to allocate our resources?
It's always better to use things that are fast. But if we have a system that can't fit entirely into this 128K, then how do I make choices about what should go where?
So how do you decide what memory should go where?
The rule of thumb is what's fast should be something that you're going to access frequently, something that you're going to be reading and writing from repetitively (going in and out, in and out a lot). Stack, and heap memory fall into that category as well, in some capacity.
Frame buffers are really just large contiguous blocks of memory, and can also come from the heap. They can’t really come from the stack, but they could certainly be defined as global variables.
If you have the opportunity to look at these classifications of memory blocks and can allocate your frame buffers from these in advance, then you can consider the speeds and characteristics of what will be rendered, to your advantage when making the best choice.
What is the best way to use memory to render a screen?
Typically when we're rendering to a display, you're not rendering just one frame buffer to the LCD screen. If you did that that every time you composed the scene, generally, you'd see the composition stages of the image. But really - I'm only interested in seeing the end result. This is where we get into various methods in which we flip the buffers that we're drawing to on to the display. It's a whole other topic for another day in terms of the different techniques that we could use. But we have choices.
So for this example, we’ll call this frame buffer 1 (FB1), and this is a frame buffer 2 (FB2) (see image below).
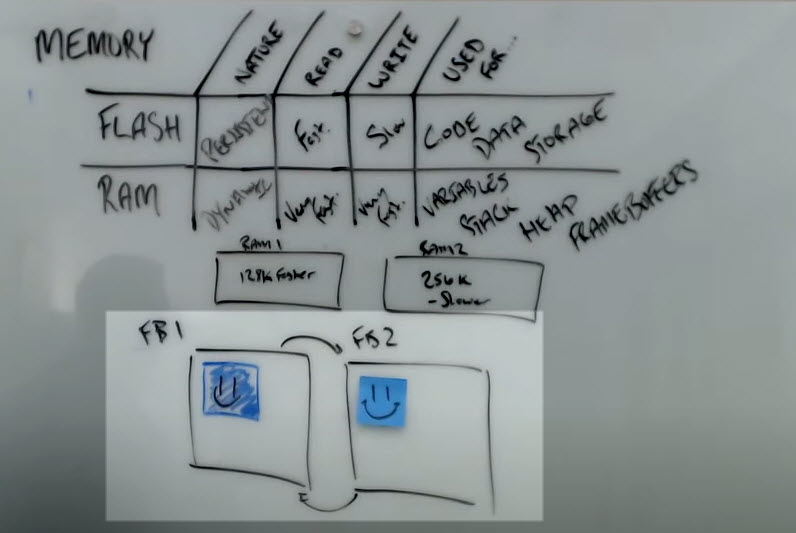
Typically we’ll drive a one frame buffer off-screen. Then we'll flip it on screen and take the other frame buffer and start drawing too. There's lots of different strategies for doing this, back buffering, double buffering, triple buffering, multi buffering, lots of different ways to approach this - but our goal is that when we go to the display, rather than seeing all the individual scene elements, we just show up with the composed element, right.
If we look at what we're doing with these allocation patterns, the offscreen buffer, because it's being composed to, is going through a lot of read, write, read, write, read, write cycles. I need to access this buffer to draw the initial content, then to read it back and compose in overlay content. I might do that many, many, many different times. But if this is my primary buffer going to the display, I really only need to write that once.
Which memory should frame buffers should go in?
So if we look at how we might use this type of RAM configuration, make some decisions about which buffers should go where, really you want this buffer with its frequent read-write access to go into this fast buffers area if we could make it fit. And then ideally, if we could make them all fit, we put them all in the fast buffer.
However, it might be a very acceptable trade-off to put this buffer into the slower access area because we're only going to write to it really once. And then the display will access it. Here, maybe by putting this buffer in here, we segment it and we give ourselves a little bit of access space for stacks, for some other variables that we want to access more frequently, right. So it's an important consideration for how we use the memory.
Wrap-up
So, in summary, lots of different things to know about embedded memory and things to consider. In our next next session, we're going to talk about how you compose a very rich UI without really running into this fragmentation issue, having to leverage the heap and the dynamic memory allocation, being able to pull content directly from flash, being able to encode our images and our font data directly into storage which is slow to write but fast to read, at least fast enough for our embedded user interfaces. That leaves us with the ability to leverage the RAM, which is very fast for both reading and writing for things like our frame buffer in our composition story.
Live questions -
Where should I put the frame buffer SRAM, or SDRAM?
It's not necessarily a question of one or the other. It's really a matter of taking a look at your access patterns, right? So if you can put your back buffer into your faster RAM, so that would be your SRAM, not your SDRAM and then your primary buffer into the SDRAM. SDRAM being slower than SRAM, then that's what I would recommend you to do.
How much stack and heap do I need to allocate peak versus steady state?
That's an excellent question. The answer is generally you always need to allocate your peak if you're thinking about stack, because the challenge is is that if you don't allocate for your peak, you run the risk of a stack overflow at some point in time during your execution.
The steady state operation may be much lower, but these are the type of things that want to analyze during your execution and say, well, are there ways that we could actually mitigate that high cost? Maybe what you've got is you've got a heavily recursive function which forces your stack usage to go high, but on a natural kind of growth.
You could turn that into more of an iterative approach, where it's a little bit more linear, and your stack growth isn't going to go out of control and then that lowers your overall footprint.
There are most embedded operating system offer us various tools by which we can kind of scribble in to the stack in advance, then run our programs and actually take a look and see how far did you get up, what was that high watermark.